
3. INTEGRACIÓN DE LAS IDEAS DE LA WEB SEMÁNTICA Y LA WEB 2.0
Como ya se señaló en la sección 1 Tim Berners-Lee pensó originalmente en una Web de lectura/escritura, aunque luego la Web se utilizó como un medio de sólo lectura para la mayoría de los usuarios. En década de los 90 era muy similar a la combinación de una agenda telefónica y las páginas amarillas (una mezcla de los distintos anuncios y catálogos de empresas) y, a pesar del poder de conexión de los hipervínculos, existía poco sentido de comunidad entre los usuarios. Esta actitud pasiva hacia la Web se quebró cuando se realizaron una serie de cambios en los patrones de uso de la tecnología, que derivaron en lo que ahora se conoce como la Web 2.0, una palabra acuñada por Tim O’Reilly.
Los cambios que condujeron al actual nivel de compromiso social en línea, no han sido radicales o individualmente significativos, lo que explica que el término Web 2.0 se ha creado en gran medida después de los hechos, sin embargo, este conjunto de innovaciones en la arquitectura y los patrones de uso de la Web ha dado lugar a un papel totalmente diferente del mundo en línea como plataforma para la comunicación y la interacción social. El consiguiente aumento de la capacidad para obtener información y colaboración social en línea puede ser cuantificado.
La primera oleada de la socialización en la Web fue gracias a la aparición de los blogs, las wikis y otras formas de comunicación y colaboración basadas en la Web. Los Blogs y las wikis obtuvieron una masiva popularidad alrededor del año 2003 (véase la Fig. 6).
Ambas herramientas tienen en común la facilidad para añadir contenido a la Web, ya que para la edición de los blogs y las wikis no se requiere ningún conocimiento de HTML o algún otro lenguaje de programación. Estas herramientas permiten a las personas o grupos tener su propio espacio personal en la Web y agregar contenido con facilidad. A pesar de que los weblogs en sus inicios fueron utilizados puramente para publicar cosas personales (como si fuera un diario), hoy en día BlogSphere es ampliamente reconocida como una red social interconectada a través de la cual las noticias, ideas e influencias se transmiten rápidamente haciendo referencia o un comentario sobre lo publicado en otros blogs.
Aunque la Wikipedia es un ejemplo excelente, tanto las wikis grandes como pequeñas son utilizadas por grupos de distintos tamaños como una herramienta efectiva para gestionar los conocimientos almacenados y desarrollar ideas conjuntamente.
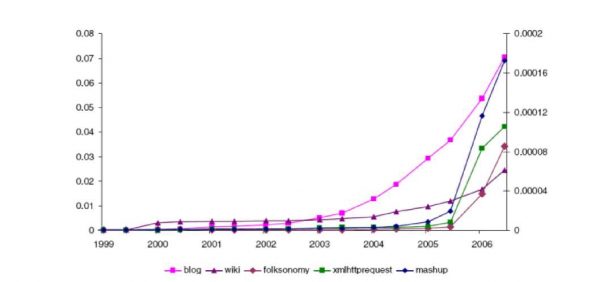
Fig. 6 : Desarrollo de la red social. La proporción de páginas con los términos blogs, wiki en el tiempo se muestra en el eje izquierdo. La proporción de sitios con los términos folksonomy, XmlHttpRequest y mashup se mide en el eje derecho.
Sin importar el objetivo, la propiedad colectiva de una Wiki da sentido de comunidad (o al contrario revela una falta de cohesión del grupo) a través de discusiones que se generan sobre contenidos compartidos. Es así como las primeras redes sociales en línea nacieron al mismo tiempo que comenzó el auge de los blogs y las wikis.
Existen servicios que usan los perfiles de usuarios y las redes para estimular diferentes tipos de intercambio, como puede ser Flickr para intercambio de fotos o Del.icio.us para el intercambio de páginas favoritas. Muchos de estos sistemas se basan en el etiquetado colaborativo (folksonomías) para conectar a los usuarios con contenidos y otros usuarios interesados en temas similares. Al igual que las wikis, este nuevo tipo de sitios tienen como objetivo dar un rol activo a la comunidad de usuarios en la creación, mantenimiento y organización del contenido.
Los perfiles explícitos de los usuarios permiten a estos sistemas introducir mecanismos de calificación (ratings) en donde los usuarios o sus contribuciones son puestas en una tabla de posiciones (ranking) de acuerdo a su pertinencia o veracidad. Las tablas son formas explicitas de capital social que regulan los intercambios en las comunidades en línea de la misma manera que la reputación en el mundo real. Además este sistema ofrece la posibilidad a los usuarios de ver lo que otros usuarios están haciendo en tiempo real, dando la sensación de estar aún más conectado, con los miembros en línea en ese momento.
Así como las redes sociales, otro estandarte de la Web 2.0 es el diseño e implementación de aplicaciones web, que han evolucionado para mejorar la experiencia del usuario de interactuar con esta de una forma fluida y amigable.
En términos de diseño, los nuevos sitios web ponen énfasis en una interfaz de apariencia clara, accesible y atractiva que interfiera lo menos posible en la funcionalidad de la aplicación.
En términos de implementación, los nuevos sitios web se basan en novedosas formas de aplicar algunas de las tecnologías preexistentes (JavaScript asincrono y XML, también conocido como AJAX).
En consonancia con la facilidad de uso, se puede observar también una preferencia por formatos, lenguajes y protocolos que son fáciles de utilizar y desarrollar. Es el caso de lenguajes como JSON (“JavaScript Object Notation”, es un formato ligero para el intercambio de datos) y protocolos como REST (Representational State Transfer, REST es una técnica de arquitectura software para sistemas hipermedia).
Esto da como resultado que se pueda acelerar el desarrollo de prototipos y aplicaciones, también ayuda la ideología del movimiento de software de código abierto, posibilitando que las aplicaciones Web 2.0 provean libremente sus datos y servicios para que los usuarios puedan experimentar con ellos.
¿Pero cómo se relaciona la Web Semántica con la Web 2.0? Para algunos suele ser una percepción común que la Web 2.0 y la Web Semántica son visiones contrastadas que compiten por el futuro de la Web. En este sentido la Web Semántica es un esfuerzo de la W3C para desarrollar una Web con tecnología semántica. En la práctica las ideas de Web 2.0 y de Web Semántica no son excluyentes: mientras la Web 2.0 pone énfasis sobre todo en cómo los usuarios interactúan con la Web, la Web Semántica abre nuevas oportunidades tecnológicas para los desarrolladores a la hora de combinar datos y servicios de diversas fuentes.
Por ejemplo, una premisa básica de la Web 2.0 es que los usuarios están dispuestos a proporcionar contenidos y metadatos. Estos contenidos pueden tomar forma de artículos y hechos organizados en tablas y categorías como en Wikipedia, fotos organizadas en álbumes de acuerdo a tags como en Flickr o información estructurada embebida en páginas principales y blogs en forma de microformatos.
Otra premisa de la Web 2.0 es que debido a la extensiva colaboración en linea, muchas aplicaciones tienen acceso a muchos metadatos sobre los usuarios. Información sobre las opciones, las preferencias, el gusto y las redes sociales de usuarios significa para las nuevas aplicaciones la posibilidad de construir perfiles mucho más ricos de un usuario. Claramente, la tecnología semántica puede ayudar a encontrar usuarios con las mismas preferencias, como así también contenido disponible relacionado, sin embargo, la semántica no es suficiente, ya que hay una componente de confianza que está más allá de las inferencias que se pueden hacer basadas en los perfiles. Por lo tanto los sistemas semántico-sociales pueden proporcionar recomendaciones basadas tanto en las redes sociales de usuarios y sus perfiles personales, como en mecanismos basados puramente en redes de confianza.
Por otra parte lo que la tecnología de la Web Semántica puede ofrecer a la comunidad del Web 2.0 es una infraestructura estándar para construir combinaciones creativas de datos y de servicios. Por ejemplo, FreeBase es una base de datos abierta que contiene información acerca del mundo, y permite que los usuarios compartan, enlacen, y corrijan conjuntamente ontologías y datos estructurados a través de una interfaz web.
A esta combinación de visiones y tecnologías es a la que los expertos han denominado Web 3.0.
La figura 7 muestra como la aplicación de las tecnologías de la Web Semántica extienden a la bien conocida Web 2.0, éstas en conjunto forman lo que hoy se conoce como Web 3.0.

Ejemplos de aplicaciones que actualmente combinen estas dos estrategias y que se puedan considerar Web 3.0
En esta sección se presentan dos ejemplos emblemáticos de aplicaciones Web 3.0. En primer lugar Twine, como red social abierta y después WEASEL, una red social corporativa.
EL caso Twine:
Desde el lanzamiento de su versión beta, los usuarios de Twine han mantenido sesiones de una duración media de 6 minutos al día, y recientemente ha aumentado a 12 minutos superando a MySpace y casi alcanzando los tiempos de 15 minutos de los usuarios del popular Facebook, toda una proeza para una red social que ha sido presentada al público hace tan sólo unos días por Radar Networks. Lo que justifica este temprano y anticipado éxito de Twine, así como la expectación que ha suscitado su anunciado lanzamiento, no es tan sólo el hecho de que sea un eficaz buscador y un innovador gestor de contenidos, sino la incorporación de tecnologías semánticas en las que se sustenta. Esta plataforma pertenece a una nueva etapa en el desarrollo de la Web y es una de las primeras aplicaciones de la Web Semántica.
Twine utiliza el lenguaje de descripción de contenidos RDF. La Web se adentra en una nueva era comenzando a implementarse en ella recursos como el procesamiento de lenguaje natural, hasta ahora restringidos al campo de la inteligencia artificial.
Con la inclusión de RDF los gestores de contenido artificiales serán capaces no sólo de clasificar y etiquetar automáticamente los contenidos, sino de interpretar los datos.
Estas aplicaciones y herramientas semánticas llevan a nuevo nivel de evolución a la interacción hombre-máquina y también la comunicación entre las propias máquinas. La generación automática de etiquetas, descripciones y sumarios para las páginas web marcadas según los intereses del usuario es una herramienta ideal para la recopilación, el intercambio y la gestión del conocimiento.
Twine se diferencia de otras redes sociales, porque lo principal no es el “con quién”, sino el “qué”, es decir, las relaciones están al servicio del crecimiento y el enriquecimiento de los contenidos de interés para el usuario.
Según Nova Spivack, fundador de Radar Networks y máximo responsable de Twine, lo que se debe tener claro al usar esta herramienta es el “para qué” se está usando, ya que las ventajas de las tecnologías semánticas no son obvias a primera vista.
También al usar Twine por primera vez podemos tener la sensación de estar manejando una aplicación de redes sociales tradicionales, sólo cuando el contenido creado en base a nuestros intereses crece y se enriquece, será el momento en que el usuario comenzará a recibir mucho más de lo que ha aportado. Recibir más de lo que se ha aportado en lo que respecta a los contenidos de interés para el usuario será algo habitual cuando se esté interactuando con las redes de nueva generación. En este tipo de redes no se trata de multiplicar el contenido porque sí, sino más bien de descartar lo irrelevante y seleccionar lo fundamental, y eso es lo que en principio es capaz de hacer la Web Semántica. “Es fácil crear información, pero es difícil reducirla”.
Para aprovechar realmente y sacar el máximo partido de las tecnologías semánticas es necesario involucrarse en twines de contenido públicos e interactuar con otros usuarios. Los twines son como madejas de información que tienen como núcleo los intereses del usuario y alrededor de los cuales se van tejiendo los hilos de contenido relacionados con ellos. Las madejas pueden ser públicas o privadas, puede ser documentos, vídeos, fotos, marcadores, mensajes, recomendaciones de otros usuarios, etc. Esta herramienta ya está disponible para cualquier usuario, como se puede ver en la figura 8, pudiendo comenzar a utilizarla y probarla para organizar desde ella su vida en línea.
Fig. 8 : Pantalla Inicial de Twine
Vodafone – WEASEL
La compañía Vodafone es el mayor operador de telefonía celular en el mundo, da servicio a cientos de millones de clientes. En su rápida evolución y el entorno altamente competitivo, la innovación es un elemento clave para mantener el liderazgo.
Toda la información sobre las actividades del grupo de I+D de Vodafone es publicada por sus empleados en su sitio web corporativo con el objetivo de fomentar la creación y el mantenimiento de los conocimientos tecnológicos dentro de la empresa y también el descubrimiento de las redes sociales emergentes en torno a los diferentes ámbitos de especialización.
Sin embargo, la publicación de esa información en una web corporativa accesible para todo el grupo de I+D no garantizaba que los empleados conocieran de su existencia.
Además, los empleados eran libres de subir todo lo que pudieran considerar interesante o digno de una referencia futura, sin las limitaciones de estructura o formatos, por ejemplo PDF, DOC, vídeos MPEG, etc.
Otro factor negativo era que cada usuario podía almacenar la información en donde quisiera en el sitio web corporativo, lo que hacía muy difícil recuperar información útil y también hacer referencias de un recurso a otro. Estas dificultades constituían un verdadero problema para la empresa.
Este escenario incluye una serie heterogénea de páginas web y bases de datos no estructuradas relacionadas, pero físicamente disociadas

Fig. 9 : Parte de la Ontologia Usada en WEASEL
Dicha información debe ser representada de manera unificada, y debe estar disponible para que cualquier empleado de Vodafone la pueda encontrar de una manera intuitiva y natural.
La solución fue el proyecto WEASEL , que se basa en utilizar la anotación semántica automática via ontologias (Fig. 9) para facilitar la agregación de información de diferentes fuentes, de forma que se muestre información agregada y estructurada de forma comprensible a lo largo de toda la web corporativa.
La tecnología de anotación explota las fuentes textuales y anota las fuentes multimedia a través de sus descripciones.
Las ventajas que ha obtenido Vodafone con WEASEL son:
1) La información previamente dispersa se ha transformado en información consistente a lo largo de toda la Web corporativa.
2) Las anotaciones se actualizan automáticamente.
3) Los sistemas de búsqueda dan respuestas concretas en vez de listados de documentos.
4) La tecnología semántica y la estructura de la ontología facilitan la navegación por la información.
5) La interfaz de lenguaje natural (en inglés) permite que los empleados realicen consultas utilizando expresiones naturales.
6) Las respuestas que ofrece el interfaz de lenguaje natural se explican de forma simple y comprensible con lenguaje natural.
4) TENDENCIAS FUTURAS
Aunque es difícil poder aventurar cuál es el futuro de la Web, puesto que todo lo referente a la tecnología evoluciona de forma muy rápida y en direcciones que no se pueden predecir, intentaremos recoger qué tendencias existen en relación a la Web 3.0 y la Web Semántica.
Las tecnologías de la Web 3.0, en su uso de datos semánticos; se han implementado y usado a pequeña escala, principalmente en compañías para conseguir una manipulación de datos más eficiente, aunque como se ha citado en el trabajo, poco a poco van apareciendo nuevos servicios apoyados sobre la base semántica, y la tecnología va evolucionando. En los últimos años, se ha potenciado el desarrollo para trasladar estas tecnologías de inteligencia semántica al público general, pero como ya se ha dicho, es difícil predecir si tendrá éxito o la Web Semántica será posible.
El primer paso hacia la “Web 3.0” es el nacimiento de la “Data Web”, ya que los formatos en que se publica la información en Internet son dispares, como XML, RDF y microformatos; el reciente crecimiento de la tecnología SPARQL, permite un lenguaje estandarizado y una API para la búsqueda a través de bases de datos en la red. La “Data Web” permite un nuevo nivel de integración de datos y aplicación inter-operable, haciendo los datos tan accesibles y enlazables como las páginas web. La “Data Web” es el primer paso hacia la completa “Web Semántica”. En la fase “Data Web”, el objetivo es principalmente, hacer que los datos estructurados sean accesibles utilizando RDF. El escenario de la “Web Semántica” ampliará su alcance en tanto que los datos estructurados e incluso, lo que tradicionalmente se ha denominado contenido semi-estructurado (como páginas web, documentos, etc.), estén disponibles en los formatos semánticos de RDF y OWL.
Web 3.0 también ha sido utilizada para describir el camino evolutivo de la red que conduce a la inteligencia artificial. Algunos escépticos lo ven como una visión inalcanzable. Sin embargo, compañías como IBM y Google están implementando nuevas tecnologías que cosechan información sorprendente, como el hecho de hacer predicciones de canciones que serán un éxito, tomando como base información de otras webs de música. Existe también un debate sobre si la fuerza conductora tras Web 3.0 serán los sistemas inteligentes, o si la inteligencia vendrá de una forma más orgánica, es decir, de sistemas de inteligencia humana, a través de servicios colaborativos como del.icio.us, Flickr y Digg, que extraen el sentido y el orden de la red existente y cómo la gente interactúa con ella.
En relación con la dirección de la inteligencia artificial, la Web 3.0 podría ser la realización y extensión del concepto de la “Web Semántica”. Las investigaciones académicas están dirigidas a desarrollar programas que puedan razonar, basados en descripciones lógicas y agentes inteligentes. Dichas aplicaciones, pueden llevar a cabo razonamientos lógicos utilizando reglas que expresan relaciones lógicas entre conceptos y datos en la red. Sramana Mitra difiere con la idea de que la “Web Semántica” será la esencia de la nueva generación de Internet y propone la fórmula para encapsular Web 3.0 que ya se ha presentado antes.
Otro posible camino para la Web 3.0 es la dirección hacia la visión 3D, liderada por el Web 3D Consortium. Esto implicaría la transformación de la Web en una serie de espacios 3D, llevando más lejos el concepto propuesto por Second Life. Esto podría abrir nuevas formas de conectar y colaborar, utilizando espacios tridimensionales.
De todas formas, la Web Semántica en parte se encuentra mucho más cerca de lo que pensamos. De hecho, algunas de sus aplicaciones ya están incorporadas desde hace tiempo en nuestra vida internauta cotidiana. Un buen ejemplo de ello son los ficheros RSS. Se trata de
formatos RDF basados en XML que permiten organizar y distribuir información según las preferencias de los usuarios. Los RSS contienen metadatos sobre fuentes de información suscritas que avisan a los usuarios que los recursos han cambiado y muestran los nuevos contenidos sin tener que acudir directamente a la página. Otras aplicaciones actuales son los buscadores semánticos, algunos ejemplos;
- AskWiki: Buscador para la Wikipedia [11] .
- Ayuntamiento de Zaragoza: Buscador de la web del Ayuntamiento de la ciudad[12] .
- Buscador del BOPA (Boletín Oficial del Principado de Asturias) [13] .
- Hakia: Buscador basado en ontologías semánticas [14] .
- Semantic web search [15] .
- Swoogle: Otro buscador web semántico [16] .
- PiggyBank: Navegador web semántico [17] .
- PowerAqua: Un sistema que ofrece respuestas a preguntas [18]
Por tanto ya hay ejemplos operativos y el futuro de la Web es la semántica, ¿pero cuál es el futuro de la Web Semántica?
Idealmente pretende ser un entorno más estructurado, con muchas más posibilidades para los ordenadores. Así, la Web Semántica parece estar siguiendo sus lentos pasos hacia la utopía de la información universal organizada.
Con estas bases, ¿qué proyectos de investigación se están llevando a cabo en relación a la Web Semántica?
Nepomuk
El “Proyecto Nepomuk”, que cuenta con el apoyo de la Unión Europea, tiene como objetivo “darle sentido” a la información que poseemos gracias a la creación de un escritorio semántico. Al mismo tiempo, este escritorio será social, ya que se podrá compartir información de forma sencilla, utilizando términos cotidianos para nosotros, pero que el ordenador podrá entender a la perfección. Éste es el inconveniente principal al que todos los proyectos basados en semántica se enfrentan. Tanto los ordenadores como la red poseen información, pero no pueden entenderla porque ésta sólo puede ser leída por humanos.
SEA
Investigadores de la Universidad de Stanford están realizando pruebas con una tecnología llamada SEA (dirección de correo semántico, por sus siglas en inglés) que tiene como objetivo cambiar y simplificar la forma en la que se envían los mensajes de correo electrónico. Mediante SEA, se puede enviar un e-mail sin saber exactamente cuál es la dirección del destinatario.
Basta con introducir conceptos como su nombre, su cargo u otro tipo de características descriptivas. Si el receptor cambia su dirección de correo electrónico, el sistema lo detecta y reenvía el correo a la nueva dirección de forma automática.
Uno de los objetivos que pretende alcanzar este sistema es que llegue un paso más allá, y que permita enviar correos sin saber necesariamente quién debe recibirlo. En esa nueva catalogación de los correos, basta con realizar una descripción del destinatario en función de unos parámetros para que el correo llegue a su destino. Para el presidente de Isoco, empresa española que desarrolla buscadores inteligentes basados en el contexto, Jesús Contreras, la iniciativa SEA ha sabido aunar el espíritu de las redes sociales con la necesidad de ofrecer contenido según las necesidades.
5) DEBILIDADES Y RIESGOS DEL FUTURO DE LA WEB 3.0
Aunque ya se hayan detectado aplicaciones y servicios basados en la Web Semántica, la completa implantación de la misma está aún lejos. Este sistema, construido sobre ontologías, estructuras y metadatos, para la representación formal y común de las ideas/conceptos/términos utilizados en un campo específico, no es en absoluto trivial ni gratuito. Su coste repercute en una mayor complejidad de la propia estructuración del conocimiento y de los algoritmos que permiten su gestión, lo que implica también una reducción en la eficiencia. La propia evolución de los sistemas de cómputo seguramente permitirá que, a mediano plazo, estas implementaciones sean eficientes y constituyan una alternativa que, hoy no está tan clara.
En este sentido un paso intermedio es el uso de soluciones híbridas en las que se combinen formalismos (ontologías) con estructuras no-formales (folksonomías). Estas estructuras de datos permitirían soluciones más eficientes, aunque menos versátiles. Extrayendo de la wikipedia una buena definición de lo que dicen que está por venir:
“El límite de la Web Semántica está dado no por las máquinas o sistemas biológicos que se pudieran usar, sino porque la lógica con que se intenta construir carece del uso del tiempo, ya que la lógica formal es puramente metonímica y carece de la metáfora, y eso es lo que marcan los teoremas de Godel, la tautología final de toda construcción y /o lenguaje metonímico (matemático), que lleva a contradicciones.”
El problema está en que se pretende construir un sistema inteligente que sustituya nuestro pensamiento, al menos en las búsquedas de información, pero la particularidad de nuestro pensamiento es el uso del tiempo, el que permite terminar una acción, pero esto no puede ser reproducible en las máquinas.
Con la aparición de nuevas tecnologías y propuestas, nacerán debilidades contra los que habrá que luchar, por ejemplo el SPAM semántico. ¿Quién puede asegurar que nadie intentará engañar a las futuras aplicaciones? ¿Se podrá crear una Web X.0 totalmente segura y confiable?
6) EVOLUCIÓN DE ESTE CAMPO SEGÚN LOS EXPERTOS
La evolución de la Web ya se ha tratado en este trabajo, detallando los conceptos de Web 1.0, Web 2.0, Web 3.0 y Web Semántica. En la siguiente figura se puede ver una línea de evolución tecnológica de acuerdo con Nova Spivack, miembro de la compañía americana Radar Networks. En ella se ilustra todo el trayecto desde la “prehistoria” de los ordenadores personales hasta la futura Web 4.0 (o WebOS)

Supuestamente hasta el 2020, la World Wide Web estará ingresando en una nueva fase evolutiva, la Web 3.0, una denominación seguida por cierto sector y rechazada por otro. No todos tienen claro dónde termina la Web 2.0; incluyendo a Sir Timothy Berners Lee, el propio “inventor” de la Internet y director del World Wide Web Consortium (W3C), el organismo que supervisa el desarrollo de la gran red y establece sus convenciones. Realmente no todos permiten llamar Web 3.0 al cambio que se aproxima.
Sir Berners-Lee en una conferencia realizada en Marzo de 2006 hablaba sobre la Web Semántica y las posibilidades que puede ofrecer a los futuros servicios. Un punto común en su discurso con otras muchas personas es la problemática para poder catalogar toda la información, y componer los metadatos para todos los recursos, más aún si son a través de ontologías estructuradas, puesto que requieren aún más esfuerzo. Aunque él, como impulsor de la idea, es optimista. Exponía además ciertos puntos sobre los que se fundamenta el futuro de la Web Semántica:
- Mayor poder de integración de la información, necesitando una conciencia más estricta y más transparencia en los servicios
- Mayor poder en el análisis de datos por parte de los ordenadores, que permitirá mayor estabilidad y nuevas oportunidades.
- Nuevas ideas, nuevos sistemas y por tanto, nuevas reglas.
- Un nuevo campo: La Web Science.
Actualmente la Web consigue la comunicación y entendimiento entre humanos y máquinas, pero para conseguir la comunicación y entendimiento entre máquinas, se tiene que conseguir que la información introducida por los usuarios sea estructurada de forma que las máquinas puedan comprenderla, y este proceso no es inmediato.
Por tanto, en la actualidad esto sólo es posible si limitamos mucho el campo de la información que deseamos introducir, pero seguramente en un futuro se conseguirá solucionar este problema y entonces empezará a tener sentido pensar en la Web Semántica. Mientras tanto, seguirán apareciendo aplicaciones basadas en información muy concreta, pero no se podrán extrapolar a algo más global.
bibliografía
- Sitio para compartir fotos, videos, blogs, etc.: technorati.com
- Proyecto para facilitar la transferencia entre usuarios de fotos, videos, etc. http://www.parakey.com
- Sitio de Amazon que promueve lo que llaman HITs (Human Intelligence Tasks).http://www. com
- Spivack, Nova. “Does the Semantic Web = Web 3.0?”. [En línea]. 2006. Disponible en: http://novaspivack.typepad.com/nova_spivacks_weblog/2006/11/does_the_semant.html
- Web 2.0 journal, SYS-CON Media Inc. “Forget Web 2.0, says Berners-Lee: ‘Web 1.0 was already all about connecting people’.” [En línea]. 2006. Disponible en: http://web2.sys- con.com/read/263602_p.html
- Brodkin, Jon. “Gartner touts Web 2.0, scoffs at sequel.” [En línea]. Network World. Disponible en: http://www.networkworld.com/news/2007/092107-gartner-web-20.html?page=3
- Spalding, Steve. “How To Define Web 3.0.” [En línea]. 2007. Disponible en: http://howtosplitanatom.com/news/how-to-define-web-30-2
- Chandler, Jeff. “Interview With Steve Spalding.” [En línea]. 2007. Disponible en: http://www2.ub.edu/bid/consulta_articulos.php?fichero=17serra2.html
- Spivack, Nova. “Web 3.0 — The Best Official Definition Imaginable.” [En línea]. 2007. Disponible en: http://novaspivack.typepad.com/nova_spivacks_weblog/2007/10/web- 30—the-a.html
- O’Reilly, Tim. “Today’s Web 3.0 Nonsense Blogstorm” [En línea]. Disponible en: http://radar.oreilly.com/archives/2007/10/todays-web-30-nonsense-blogsto.html
- Askwiki, un motor de búsqueda semántico: http://askwiki.com
- Buscador semántico de trámites en línea del Ayuntamiento de Zaragoza: http://www.zaragoza.es/tramites
- Boletín oficial del Principado de Asturias: http://bopa.fundacionctic.org
- Buscador semántico hakia: http://www.hakia.com
- Buscador web semántico: http://www.semanticwebsearch.com/query/
- Buscador web semántico swoogle: http://swoogle.umbc.edu
- Piggy Bank, plugin para Firefox: http://simile.mit.edu/piggy-bank/
- Sistema de respuesta a preguntas basado en ontologías: http://technologies.kmi.open.ac.uk/poweraqua/
La integración de las ideas de la Web Semántica y la Web representa un paso significativo en la evolución de la World Wide Web.
- Web Semántica:
- La Web Semántica es una iniciativa que busca agregar significado y contexto a la información en la web, permitiendo a las máquinas comprender el contenido de manera más inteligente.
- Utiliza estándares como RDF (Resource Description Framework), OWL (Web Ontology Language) y SPARQL (Protocol and RDF Query Language) para estructurar los datos de manera que las relaciones y significados sean más claros tanto para humanos como para máquinas.
- La Web Semántica se enfoca en la representación y relación de datos a través de metadatos enriquecidos.
- Web 3.0 y la Integración:
- La Web Semántica se considera una parte esencial del concepto más amplio de Web 3.0, que busca una web más inteligente y colaborativa.
- En la Web 3.0, la información está interconectada de manera más significativa, y los sistemas pueden realizar inferencias y comprender el contexto de manera más avanzada.
- La integración de la Web Semántica en la Web 3.0 implica la creación de una red más inteligente y eficiente, donde la información es fácilmente accesible y comprensible para las máquinas, facilitando así la automatización y la toma de decisiones informada.
- Beneficios de la Integración:
- Interoperabilidad:
- La Web Semántica permite una mejor interoperabilidad entre diferentes sistemas al definir claramente las relaciones y significados entre los datos.
- Esto facilita la integración de información desde diversas fuentes, creando un entorno más cohesivo.
- Descubrimiento de Conocimiento:
- La Web Semántica, al enriquecer los datos con metadatos semánticos, facilita el descubrimiento de conocimiento al permitir que las máquinas comprendan la información de manera más contextual.
- Personalización y Experiencia del Usuario:
- La integración de la Web Semántica puede mejorar la personalización de la experiencia del usuario al comprender mejor las preferencias y necesidades individuales.
- Interoperabilidad:
- Desafíos y Consideraciones:
- Privacidad y Seguridad:
- La integración de estas tecnologías requiere consideraciones cuidadosas sobre la privacidad y la seguridad de los datos, especialmente cuando se trata de la cantidad de información interconectada.
- Adopción Generalizada:
- A pesar de los beneficios, la adopción generalizada de la Web Semántica y la Web 3.0 todavía enfrenta desafíos, como la necesidad de estándares comunes y la educación sobre estas tecnologías.
- Privacidad y Seguridad: